Modern infrastructure teams are being pulled deeper into data and AI systems than ever before. Dashboards, ML models, RAG pipelines, feature stores, and real-time analytics all sit on top of infrastructure — and whenever something breaks, the first call usually goes to the Infra or SRE team.
The challenge? Most data engineering concepts are explained in ways that feel abstract, academic, or disconnected from day-to-day platform work.
This blog is for Infra Engineers, DevOps Engineers, SREs, Cloud Architects, and Platform Engineers who want a simple, practical understanding of how data actually behaves inside modern systems — without heavy theory or complex diagrams. If you manage clusters, pipelines, storage, queues, or AI workloads, these fundamentals will help you debug faster, design better, and avoid being blamed for data issues that were never infra issues to begin with.
SECTION A — Understanding Data (The Mindset Shift)
Data Is Not a File; It’s a Flow
Most engineers imagine data like this:
[file.csv]
[events.log]
[transactions/]
But this is the old mental model.
Modern data behaves like this:

Data is always moving.
It flows, waits, stacks up, delays, transforms, and eventually becomes something useful.
🔴 If the flow breaks anywhere → downstream systems break
Even while your infrastructure metrics stay 100% green.
⭐ Real Example 1 — The “Stale Dashboard” Mystery
A business dashboard shows yesterday’s numbers.
Infra team checks:
✔ API is up
✔ Kafka is healthy
✔ Kubernetes is stable
✔ Airflow job succeeded
Everything is green — but the numbers are wrong.
Root cause:
A write permission was removed from the raw storage bucket.
Data never landed.
Pipelines ran on empty input.
➡ Infra looked healthy
➡ Data flow was broken
⭐ Real Example 2 — The AI Chatbot That Lies
A chatbot is returning outdated policies.
Infra team checks:
✔ GPUs fine
✔ Model endpoint fine
✔ Vector DB fine
✔ Retrieval fine
But the answers are wrong.
Root cause:
Embedding generation job silently failed → vector index outdated.
➡ Infra fine
➡ Data flow broken
⭐ Key Insight
Data is not a thing.
Data is a movement.
Infra engineers must focus on where the flow stopped, not just where the data “is.”
SECTION B – The Modern Data Journey (Simplest Possible Map)
Every organization — bank, retail, insurance, SaaS — follows this same flow:

Let’s keep each layer simple:
1. Sources
→ Apps, APIs, logs, IoT, DB CDC
→ Your LB, API gateway, Kafka, Pub/Sub
2. Raw Storage (“Landing Zone”)
→ S3 , GCS , ADLS
→ IAM, region placement, lifecycle rules matter
3. Processing (ETL/ELT/Streaming)
→ Airflow, Argo, Prefect, Spark, Kafka Streams, Flink
→ Depends entirely on your compute, network, naming consistency
4. Warehouse/Lakehouse
→ BigQuery, Snowflake, Databricks, Redshift
→ Compute scaling, partitioning, clustering, cost impact infra
5. Consumers
→ Dashboards, APIs, ML feature stores, vector DBs, AI agents
→ If this layer looks wrong → trouble starts
If you know this 5-step map, you know exactly where to debug.
⭐ Why this map matters for Infra?
It gives you a mental checklist to debug any data incident quickly.
SECTION B — How Data Breaks (Infra-Focused Failures)
Pipelines Are Conveyor Belts, Not Cron Jobs
Old mental model:

New realty:
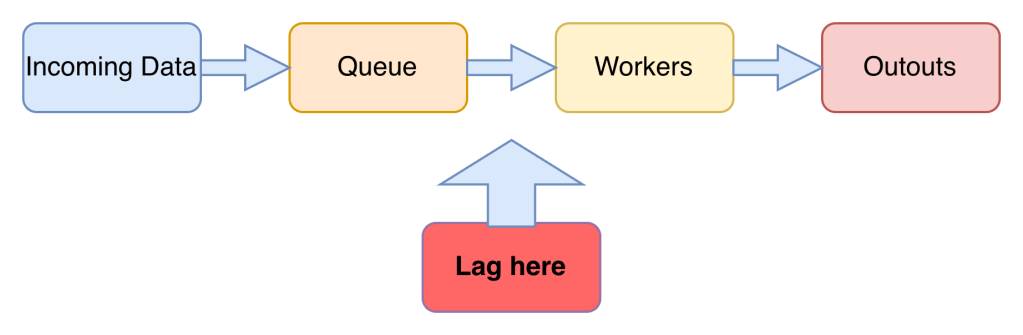
⭐ Common failures that look like infra issues:
- Consumer lag
- Backpressure
- Workers stuck on retries
- Empty input files
- Partial processing
- Out-of-order events
Infra looks fine. Data is broken.
Batch vs Streaming — How They Fail Differently
Batch (hourly/daily) = “No Output” Problem

Symptoms:
- Dashboards empty
- Pissing partitions
- Inconsistent reports
Streaming (continuous)= “Lag” Problem

Symptoms:
- Delayed metrics
- Slow fraud detection
- Delayed AI updates
- Slow API responses
Infra usually gets blamed for both.
Storage — The Heart of the Data Platform
Everything depends on object storage:
/raw
/clean
/trusted
⭐ Common storage issues:
- IAM denied → files don’t land
- Wrong folder naming → pipelines can’t find data
- Lifecycle deletes → data disappears
- Cross-region writes → latency spikes
- Trillions of small files → slow scan jobs
Storage is Infrastructure but storage issues appear as data issues.
Schema Drift — The Silent Killer
Expected: { user_id: int, ts: string }
Got: { user: string, timestamp: int }
What breaks?
- Dashboards break
- Models degrade
- Pipelines skip records
- API responses inconsistent
But:
❌ No infra metrics spike
❌ No alerts fire
❌ No pods restart
❌ No CPU changes
Everything looks green… but data is broken.
Data Quality = SLOs for Data (Infra Edition)
Think of data quality as reliability metrics:
Freshness = Latency SLO
Completeness = Coverage SLO
Correctness = Validity SLO
Consistency = Replication SLO
If SLOs for data are off, systems behave unpredictably even if the infrastructure is healthy.
SECTION C — Why Infra Must Care (Cost, Performance & AI)
Partitioning — The Hidden Root of Slow Jobs
Good: | Bad: |
/year=2025/month=01/day=10/ | /dump-folder-with-10-million-files/ |
Impacts:
- Job runtime
- Warehouse cost
- Pipeline speed
- AI data freshness
Partitioning mistakes create infra symptoms like:
- Nightly ETL spikes
- High CPU
- Long-running Spark jobs
- Increased warehouse credits
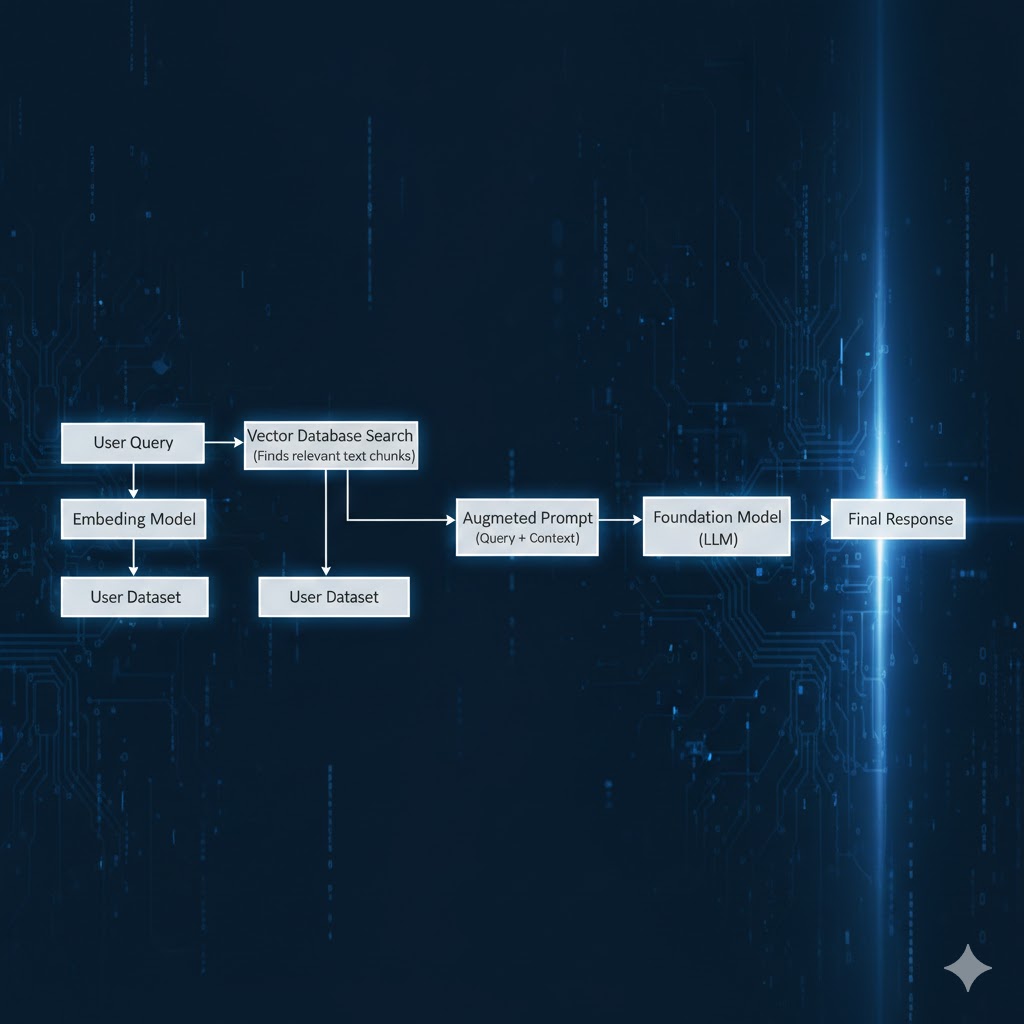
How AI Actually Uses Data
Forget the hype — here’s the real pipeline:

If any stage is broken:
- Embeddings outdated
- Vector index incomplete
- Irrelevant chunks
- Missing documents
AI answers become:
- Incorrect
- Inconsistent
- Hallucinated
- Outdated
Infra gets blamed. (Data was the problem.)
Why AI Failures Look Like Infra Failures
| Symptom | Looks like | Actually caused by |
|---|---|---|
| GPU idle | Infra scaling issue | Model starved of new data |
| Slow responses | API issue | Vector DB outdated |
| Wrong answers | Model issue | Missing embeddings |
| Alerts missing | Job scheduling issue | Streaming lag |
AI ≠ Model
AI = Data + Retrieval + Model
The One Line That Ties Everything Together
Infra Reliability + Data Reliability = AI Reliability
If you understand how data flows, you can solve issues faster, design better platforms, and support AI systems more confidently.
FINAL CONCLUSION
Modern infrastructure is data infrastructure.
Dashboards, ML systems, feature stores, vector DBs, and AI workloads all depend on one thing:
Data flowing correctly through the system.
You don’t need to become a data engineer.
But you do need to understand:
- How data moves,
- Where it gets stuck,
- How it breaks, and
- How AI depends on it.
This is the new foundational skill for Infra/DevOps/SRE engineers in the AI-driven era.



Leave a comment