
Observability, feedback loops, and the foundation of reliable AI systems
In a previous post, I explored how modern AI systems can behave intelligently yet lack any real awareness
If you haven’t read it, you can find it here: [Link to Part 1]
They can observe, reason, and act.
But they do not understand.
If that is true, the next question becomes unavoidable:
How do we trust systems that act without awareness?
When Intelligent Systems Behave, But We Don’t Understand Why
In most production systems, this pattern shows up very quickly.
An AI-driven system starts to monitor logs, detect anomalies, and trigger automated actions.
At first, it looks impressive:
- Issues are detected faster than humans
- Actions are taken automatically
- Systems recover quickly
But when something goes wrong, the experience is very different.
- You can’t clearly trace why a decision was made
- The reasoning feels opaque
- The outcome is hard to explain
The system is still functioning.
But trust starts to erode.
Trust is not built on action alone.
It is built on understanding
Observability: The Closest Thing Systems Have to Awareness
In traditional distributed systems, we rely heavily on observability:
- Logs
- Metrics
- Traces
These give us visibility into what the system is doing.
In many ways, this is the closest thing systems have to awareness, not awareness in the human sense, but visibility into behavior.
And as systems become more intelligent, this becomes even more critical.
You cannot trust what you cannot see
What Observability Actually Looks Like in AI Systems
A simplified view of an AI system and the observability layer required to build trust. Without visibility across these steps, understanding system behavior becomes extremely difficult.
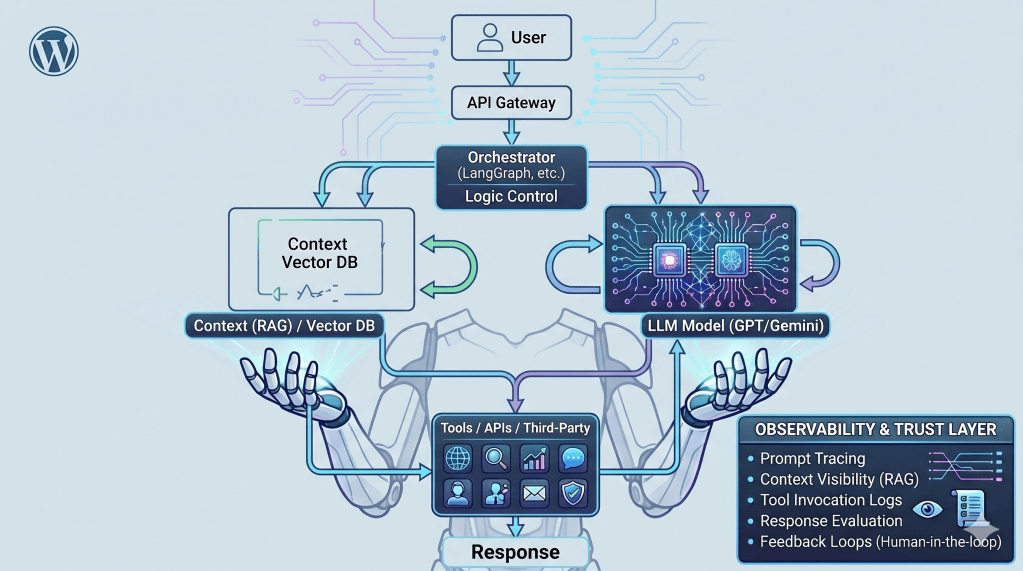
In practice, observability in AI workflows goes beyond infrastructure.
It typically includes:
- Prompt tracing — what exactly was sent to the model
- Context visibility — what data was retrieved (RAG)
- Tool invocation logs — which APIs or systems were called
- Response evaluation — what the model returned and how it was assessed
A single request often flows through multiple layers:
User Query → Prompt Construction → Context Retrieval (Vector DB)
→ LLM Call → Tool Invocation → Response → Evaluation
Internally, the system cycles through:
Think → Reason → Plan → Act → Observe → Repeat
Tools like Langfuse, OpenTelemetry-based tracing, and emerging evaluation frameworks are starting to provide visibility into these workflows.
Each step needs to be visible.
Because when something goes wrong, the failure is rarely in one place – it usually emerges from the interaction between these layers.
We are not observing what the system understands.
We are observing how it behaves.
Feedback Loops: Where Trust Begins to Form
Visibility alone is not enough.
Trust needs feedback.
In AI systems, feedback loops show up in different ways:
- Human-in-the-loop validation
- Evaluation pipelines
- Monitoring outcomes and corrections
- Iterative refinement
Without these, systems don’t just fail, they drift.
Without feedback, intelligence drifts.
Where Trust Breaks
This is where things start to get interesting – and a bit uncomfortable.
When observability is weak and feedback is missing, failure patterns emerge quickly:
- Confident but incorrect responses
- Incorrect tool usage
- Automation loops repeating the same action
- Increasing costs with no clear explanation
For example, consider a simple troubleshooting agent:
- It retrieves logs using a RAG pipeline
- It sends context to the model
- The model suggests restarting a service
- The system executes the action
If the retrieved context is incomplete or misleading:
- The model suggests the wrong action
- The system repeats it
- The issue escalates instead of resolving
Nothing is technically “broken.”
But everything is going wrong.
And without visibility into:
- What context was retrieved
- How the decision was formed
- Why that action was chosen
Debugging becomes extremely difficult.
Trust Is Not an Emergent Property – It Is Designed
In my view, this is where many AI systems start to feel unreliable, not because they fail, but because we can’t explain them.
Trust does not emerge automatically from intelligence.
It has to be designed.
Through:
- Visibility (observability)
- Correction (feedback loops)
- Boundaries (guardrails and policies)
- Oversight (human involvement where needed)
We don’t trust AI because it is intelligent. We trust it because we can understand and control its behavior.
A Subtle but Important Gap
In human terms, trust comes from awareness and accountability.
In systems, we approximate that through visibility and feedback.
But the gap is still there.
Intelligence can act. Only awareness can understand.
What Comes Next
If observability helps us see behavior, the next challenge is ensuring correctness.
Because seeing what a system does is not the same as knowing it is right.
In the next article, I’ll explore how grounding techniques like Retrieval-Augmented Generation (RAG) bring AI systems closer to reality—and where they still fall short.
Because in the end, we are not designing systems that understand.
We are designing systems that must still be understood.



Leave a comment